Opdatering 18/02/2023: Nordnet ændrer tit på deres ting. På https://github.com/helmstedt/nordnet-utilities forsøger jeg at følge med, så hent gerne din kode der, hvis koden neden for ikke virker længere.
Nordnet har fået en ny hjemmeside med en markedsoversigt, hvor man blandt andet kan finde valutakurser. Dem ville jeg gerne have fat i til et Excelark 🙂
Jeg trykkede F12 i min browser for at undersøge, hvad der sker, når jeg klikker “Valutaer” på siden, og hvad der krævedes af cookies og klient-identifikation for at få data tilbage. (Du kan læse mere om metoden i mange af mine andre programmeringsindlæg.)
Det endte med dette program, der genererer en CSV-fil med den seneste valutakurs for en række almindelige valuter fra Nordnet:
# -*- coding: utf-8 -*-
# Author: Morten Helmstedt. E-mail: helmstedt@gmail.com
""" This program gets currency data from Nordnet.
Handy for exporting to Excel with as few manual steps as possible """
import requests
# Creates a dictionary to use for cookies
cookies = {}
# Sets NEXT cookie
url = 'https://www.nordnet.dk/markedet'
r = requests.get(url)
cookies['NEXT'] = r.cookies['NEXT']
# Requests currency data
headers = {'client-id': 'NEXT'}
# Gets currency data
url = 'https://www.nordnet.dk/api/2/instrument_search/query/indicator?entity_type=CURRENCY&apply_filters=market_overview_group%3DDK_GLOBAL_MO'
r = requests.get(url, cookies=cookies, headers=headers)
currencies = r.json()
# Generate CSV output of last value by looping through currencies
output = "navn;senest\n"
for currency in currencies['results']:
name = currency['instrument_info']['name']
price = str(currency['price_info']['last']['price'])
price = price.replace(".",",")
output += name + ";" + price + "\n"
# Write CSV output to file #
with open("currency.csv", "w", encoding='utf8') as fout:
fout.write(output)
Opdateret d. 20/10/2019: Nogle gange har Saxo Bank en “disclaimer” (i dette tilfælde omkring Brexit), som de vil vise, inden man får lov at logge på. Jeg har tilpasset koden, sådan programmet kan håndtere dette tilfælde.
Nu er jeg også blevet kunde hos Saxo Bank. (Hvorfor? Mulighed for at oprette en aktiesparekonto og ingen minimumskurtage.)
Selvbetjeningsløsningen hos Saxo Bank er rigtig dårlig (sammenlignet med Nordnets).
Derfor var jeg interesseret i, om jeg kunne finde en måde at trække transaktionsdata ud fra min konto hos Saxo Bank – uden at have brug for at se på hjemmesiden.
Allerførst kiggede jeg på, hvad hjemmesiden gør, når den skal vise mine data. Jeg valgte gennemførte handler i menuen:
Og så kiggede jeg på, hvad browseren gjorde. Det viser sig at hjemmesiden – fornuftigt nok – bruger Saxo Banks API, når den skal vise data til brugeren:
Jeg kunne se, at API’et modtog en lang streng (“Authorization” med ordet BEARER foran). Den gik jeg ud fra, var nødvendig, for at få data tilbage.
Så spørgsmålet var egentlig bare: Hvordan bliver sådan en BEARER-streng genereret?
Tilbage til start
For at komme frem til, hvordan BEARER-strengen genereres, gik jeg tilbage til start: Jeg gik til loginsiden og trykkede F12 i min browser (Chrome) for at følge med i netværksforespørgslerne.
Loginsidens formular sender mit brugernavn og password af sted, sammen med en streng – “AuthnRequest” – der genereres på ny hver gang, loginsiden hentes:
I mit Python-program prøver jeg at sende sådan en formular af sted, og undersøger hvad jeg får tilbage.
# Visit login page and get AuthnRequest token value from input form
url = 'https://www.saxoinvestor.dk/Login/da/'
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
input = soup.find_all('input', {"id":"AuthnRequest"})
authnrequest = input[0]["value"]
# Login step 1: Submit username, password and token and get another token back
url = 'https://www.saxoinvestor.dk/Login/da/'
r = requests.post(url, data = {'field_userid': user, 'field_password': password, 'AuthnRequest': authnrequest})
Lidt forkortet ser det sådan her ud:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="Application-State" content="service=IDP;federated=False;env=Live;state=Ok;authenticated=True;"><meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<noscript><p><strong>Note:</strong> Since your browser does not support Javascript, you must press the Continue button to proceed.</p></noscript>
<form id="form" action="https://www.saxoinvestor.dk/investor/login.sso.ashx" method="post"><div>
<input type="hidden" name="SAMLResponse" value="PHNhbWxwOlJlc3BvbnNlIElEPSJfNjQzZGI4ODQtMDMzZi00MWVhLWE4ZjEtYzVjOWVlMWIxM2IwIiBJblJlc3BvbnNlVG89Il9mN2E3ODBlZi0yZjdmLTQyYmItODk1[...]G9uc2U+"/>
<input type="hidden" name="RelayState" value=""/>
<input type="hidden" name="PageLoadInfo" id="PageLoadInfo" value=""/></div>
<noscript><div>
<input type="submit" value="Continue"/></div></noscript></form><script type="text/javascript">function doSubmit(){var t=-1;if(window.location.hash){var m=window.location.hash.match(/\/lst\/(\d+)/);if(m) t=parseInt(m[1]);}if(t>=0 && document.getElementById("PageLoadInfo").value=='')document.getElementById("PageLoadInfo").value=t;document.forms.form.submit();}</script><script type="text/javascript">doSubmit();</script></body></html>
Og hvad er det så? En formular (“<input>”) til browsere uden Javascript, med et felt der hedder “SAMLResponse” med en lang (her forkortet) streng som værdi.
I Chrome kan jeg se, at allersidste trin. inden jeg når ind på forsiden af selvbetjeningen, faktisk er, at min browser sender “SAMLResponse” af sted til en side, der hedder “login.sso.ashx”:
Så jeg sender trygt formularen af sted med SAMLResponse-.værdien og ser, hvad jeg får tilbage:
soup = BeautifulSoup(r.text, "html.parser")
input = soup.find_all('input', {"name":"SAMLResponse"})
samlresponse = input[0]["value"]
# Login step 2: Get bearer token necessary for API requests
url = 'https://www.saxoinvestor.dk/investor/login.sso.ashx'
r = requests.post(url, data = {'SAMLResponse': samlresponse})
Og vupti: Siden videresender mig til API’et med et BEARER-token, jeg kan benytte mig af. Det får jeg fat i (og skærer lidt til) sådan her::
Og så er jeg ellers klar til at hente data fra API’et. Det starter sådan her:
# START API CALLS
# Documentation at https://www.developer.saxo/openapi/learn
# Set bearer token as header
headers = {'Authorization': bearer}
# First API request gets Client Key which is used for most API calls
# See https://www.developer.saxo/openapi/learn/the-tutorial for expected return data
url = 'https://www.saxoinvestor.dk/openapi/port/v1/clients/me'
r = requests.get(url, headers=headers)
clientdata = r.json()
clientkey = clientdata['ClientKey']
Hele programmet
Hele programmet – inklusive den måde, jeg omdanner Saxo Bank-data til samme format som Nordnets transaktionsdata – er her.
Du må gøre præcis som du har lyst til med det (på eget ansvar).
# -*- coding: utf-8 -*-
# Author: Morten Helmstedt. E-mail: helmstedt@gmail.com
"""This program logs into a Saxo Bank account and lets you make API requests."""
import requests
from datetime import datetime
from datetime import date
from bs4 import BeautifulSoup
import json
# USER ACCOUNT AND PERIOD DATA. SHOULD BE EDITED FOR YOUR NEEDS #
# Saxo user account credentials
user = '' # your user id
password = '' # your password
# Start date (start of period for transactions) and date today used for extraction of transactions
startdate = '2019-01-01'
today = date.today()
enddate = datetime.strftime(today, '%Y-%m-%d')
# LOGIN TO SAXO BANK
# Visit login page and get AuthnRequest token value from input form
url = 'https://www.saxoinvestor.dk/Login/da/'
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
input = soup.find_all('input', {"id":"AuthnRequest"})
authnrequest = input[0]["value"]
# Login step 1: Submit username, password and token and get another token back
url = 'https://www.saxoinvestor.dk/Login/da/'
r = requests.post(url, data = {'field_userid': user, 'field_password': password, 'AuthnRequest': authnrequest})
soup = BeautifulSoup(r.text, "html.parser")
input = soup.find_all('input', {"name":"SAMLResponse"})
# Most of the time this works
if input:
samlresponse = input[0]["value"]
# But sometimes there's a disclaimer that Saxo Bank would like you to accept
else:
input = soup.find_all('input')
inputs = {}
try:
for i in input:
inputs[i['name']] = i['value']
except:
pass
url = 'https://www.saxotrader.com/disclaimer'
request = requests.post(url, data=inputs)
cook = request.cookies['DisclaimerApp']
returnurl = cook[cook.find("ReturnUrl")+10:cook.find("&IsClientStation")]
url = 'https://live.logonvalidation.net/complete-app-consent/' + returnurl[returnurl.find("complete-app-consent/")+21:]
request = requests.get(url)
soup = BeautifulSoup(request.text, "html.parser")
input = soup.find_all('input', {"name":"SAMLResponse"})
samlresponse = input[0]["value"]
# Login step 2: Get bearer token necessary for API requests
url = 'https://www.saxoinvestor.dk/investor/login.sso.ashx'
r = requests.post(url, data = {'SAMLResponse': samlresponse})
bearer = r.history[0].headers['Location']
bearer = bearer[bearer.find("BEARER"):bearer.find("/exp/")]
bearer = bearer.replace("%20"," ")
# START API CALLS
# Documentation at https://www.developer.saxo/openapi/learn
# Set bearer token as header
headers = {'Authorization': bearer}
# First API request gets Client Key which is used for most API calls
# See https://www.developer.saxo/openapi/learn/the-tutorial for expected return data
url = 'https://www.saxoinvestor.dk/openapi/port/v1/clients/me'
r = requests.get(url, headers=headers)
clientdata = r.json()
clientkey = clientdata['ClientKey']
# Example API call #1
url = 'https://www.saxoinvestor.dk/openapi/cs/v1/reports/aggregatedAmounts/' + clientkey + '/' + startdate + '/' + enddate + '/'
r = requests.get(url, headers=headers)
data = r.json()
# Working on that data to add some transaction types to personal system
saxoaccountname = "Aktiesparekonto: Saxo Bank"
currency = "DKK"
saxotransactions = ""
for item in data['Data']:
if item['AffectsBalance'] == True:
date = item['Date']
amount = item['Amount']
amount_str = str(amount).replace(".",",")
if item['UnderlyingInstrumentDescription'] == 'Cash deposit or withdrawal' or item['UnderlyingInstrumentDescription'] == 'Cash inter-account transfer':
if amount > 0:
transactiontype = 'INDBETALING'
elif amount < 0:
transactiontype = 'HÆVNING'
saxotransactions += ";" + date + ";" + date + ";" + date + ";" + transactiontype + ";;;;;;;;" + amount_str + ";" + currency + ";;;;;;;;;" + saxoaccountname + "\r\n"
if item['AmountTypeName'] == 'Corporate Actions - Cash Dividends':
transactiontype = "UDB."
if item['InstrumentDescription'] == "Novo Nordisk B A/S":
paper = "Novo B"
papertype = "Aktie"
if item['InstrumentDescription'] == "Tryg A/S":
paper = "TRYG"
papertype = "Aktie"
saxotransactions += ";" + date + ";" + date + ";" + date + ";" + transactiontype + ";" + paper + ";" + papertype + ";;;;;;" + amount_str + ";" + currency + ";;;;;;;;;" + saxoaccountname + "\n"
# Example API call #2
url = "https://www.saxoinvestor.dk/openapi/cs/v1/reports/trades/" + clientkey + "?fromDate=" + startdate + "&" + "toDate=" + enddate
r = requests.get(url, headers=headers)
data = r.json()
# Working on that data to add trades to personal system
for item in data['Data']:
date = item['AdjustedTradeDate']
numberofpapers = str(int(item['Amount']))
amount_str = str(item['BookedAmountAccountCurrency']).replace(".",",")
priceperpaper = str(item['BookedAmountAccountCurrency'] / item['Amount']).replace(".",",")
if item['TradeEventType'] == 'Bought':
transactiontype = "KØBT"
if item['AssetType'] == 'Stock':
papertype = "Aktie"
if item['InstrumentDescription'] == "Novo Nordisk B A/S":
paper = "Novo B"
isin = "DK0060534915"
if item['InstrumentDescription'] == "Tryg A/S":
paper = "TRYG"
isin = "DK0060636678"
saxotransactions += ";" + date + ";" + date + ";" + date + ";" + transactiontype + ";" + paper + ";" + papertype + ";" + isin + ";" + numberofpapers + ";" + priceperpaper + ";;;" + amount_str + ";" + currency + ";;;;;;;;;" + saxoaccountname + "\n"
Opdatering 18/02/2023: Nordnet ændrer tit på deres ting. På https://github.com/helmstedt/nordnet-utilities forsøger jeg at følge med, så hent gerne din kode der, hvis koden neden for ikke virker længere.
OPDATERING: Nordnet er ude i en ny version, som gør at man foreløbig er nødt til at ændre URLs i programmet til “classic.nordnet.dk” for at bruge den gamle version. På et tidspunkt virker det nok heller ikke længere. Jeg har opdateret koden neden for med den korrekte url.
I dag handler det om at få fat i kurser på værdipapirer, sådan man kan lave flotte grafer i Excel over den historiske udvikling.
Sådan kan en oversigt se ud i Excel. Der er små “huller” i kurserne for enkelte papirer. Jeg har ikke undersøgt nærmere hvorfor der ikke er kurser for de datoer.
Du behøver ikke at være kunde hos Nordnet og du kan – så vidt jeg kan se – udtrække helt aktuelle realtidskurser uden forsinkelse.
Sådan gjorde jeg
Jeg startede med at besøge et værdipapir på Nordnet. Her lagde jeg mærke til den fine graf over kursudviklingen. Sådan en graf må få data et sted fra. Jeg trykkede F12 for at åbne Developer Tools og kiggede på fanen Network. Når jeg ændrede periode for grafen, kunne jeg se, at der blev sendt en ny forespørgsel af sted:
En fin kursgraf fra Nordnet. Når jeg ændrer periode, kan jeg se, at Nordnet spørger om data. På billedet kan man se, at data bliver returneret i JSON-format med forskellige kursoplysninger og et tidsstempel.
Under fanen Headers kan jeg se oplysninger om, hvad for en URL, min browser sender forespørgsler til, og hvad den spørger om:
ForespørgslenParametre
I Python bygger jeg et program, der kan løbe en liste værdipapirer igennem. Jeg opdager et enkelt værdipapir, som ikke findes hos Nordnet. Derfor bygger jeg også et slags fallback, der kan hente kursdata fra Morningstar (med 15 minutters forsinkelse).
Det færdige program i Python
Her er så det færdige program i Python. Du er velkommen til at bruge det, videreudvikle, og hvad du ellers har lyst til.
# -*- coding: utf-8 -*-
# Author: Morten Helmstedt. E-mail: helmstedt@gmail.com
""" This program extracts historical stock prices from Nordnet (and Morningstar as a fallback) """
import requests
from datetime import datetime
from datetime import date
import os
import json
# DATE AND STOCK DATA. SHOULD BE EDITED FOR YOUR NEEDS #
# Start date (start of historical price period) and date today used as standard enddate for price period
startdate = '2013-01-01'
today = date.today()
enddate = str(today)
# List of shares to look up prices for.
# Format is: Name, Morningstar id, Nordnet stock identifier, Nordnet market number
# See e.g. https://www.nordnet.dk/mux/web/marknaden/aktiehemsidan/index.html?identifier=4804&marketid=14
# (identifier is 4804, market is 14)
# All shares must have a name (whatever you like). To get prices they must either have a Nordnet identifier
# and market number or a Morningstar id
sharelist = [
["Maj Invest Globale Obligationer","F0GBR064US",36432,14],
["Novo Nordisk B A/S","0P0000A5BQ",1158,14],
["BlackRock iShares Core S&P 500 UCITS ETF","0P0000OO21]22]1]","SXR8",4],
["Nordnet Superfonden Danmark","F00000TH8X","",""],
["Danske Invest Global Indeks Akk KL DKK h","F0GBR04EPX",38898,14]
]
# CREATE OUTPUT FOLDER AND VARIABLES FOR LATER USE. #
# Checking that we have an output folder to save our csv file
if not os.path.exists("./output"):
os.makedirs("./output")
# A variable to store historical prices before saving to csv
finalresult = ""
finalresult += '"date";"price";"instrument"' + '\n'
# LOOPS TO REQUEST HISTORICAL PRICES AT NORDNET AND MORNINGSTAR #
# Nordnet loop to get historical prices
for share in sharelist:
# Nordnet stock identifier and market number must both exist
if share[2] and share[3]:
url = "https://classic.nordnet.dk/graph/instrument/" + str(share[3]) + "/" + str(share[2])
payload = {"from": startdate, "to": enddate, "fields": "last"}
data = requests.get(url, params=payload)
result = data.text
jsondecode = json.loads(result)
# Sometimes the final date is returned twice. A list is created to check for duplicates.
datelist = []
for value in jsondecode:
price = str(value['last'])
price = price.replace(".",",")
date = datetime.fromtimestamp(value['time'] / 1000)
date = datetime.strftime(date, '%Y-%m-%d')
# Only adds a date if it has not been added before
if date not in datelist:
datelist.append(date)
finalresult += '"' + date + '"' + ";" + '"' + price + '"' + ";" + '"' + share[0] + '"' + "\n"
# Morningstar loop to get historical prices
for share in sharelist:
# Only runs for one specific fund in this instance
if share[0] == "Nordnet Superfonden Danmark":
payload = {"id": share[1], "currencyId": "DKK", "idtype": "Morningstar", "frequency": "daily", "startDate": startdate, "outputType": "COMPACTJSON"}
data = requests.get("http://tools.morningstar.dk/api/rest.svc/timeseries_price/nen6ere626", params=payload)
result = data.text
jsondecode = json.loads(result)
for lists in jsondecode:
price = str(lists[1])
price = price.replace(".",",")
date = datetime.fromtimestamp(lists[0] / 1000)
date = datetime.strftime(date, '%Y-%m-%d')
finalresult += '"' + date + '"' + ";" + '"' + price + '"' + ";" + '"' + share[0] + '"' + "\n"
# WRITE CSV OUTPUT TO FILE #
with open("./output/kurser1.csv", "w", newline='', encoding='utf8') as fout:
fout.write(finalresult)
Opdatering 18/02/2023: Nordnet ændrer tit på deres ting. På https://github.com/helmstedt/nordnet-utilities forsøger jeg at følge med, så hent gerne din kode der, hvis koden neden for ikke virker længere.
OPDATERING: Nordnet er ude i en ny version, som gør at man foreløbig er nødt til at ændre URLs i programmet til “classic.nordnet.dk” for at bruge den gamle version. På et tidspunkt virker det nok heller ikke længere. Jeg har opdateret koden neden for med den korrekte url.
Jeg kan godt lide at bruge Excel til at holde øje med min økonomi, så jeg har et ark med en pivottabel, som jeg bruger til at få overblik over min portefølje hos Nordnet. Nordnet har en funktion til at trække en CSV-fil med en oversigt over mine transaktioner, men det er lidt besværligt at skulle a) logge ind på Nordnet for derefter b) at gå ind på hver enkelt depot og c) trække en ny oversigt og copy/paste hver gang, der fx udbetales udbytte.
Her klikker du hos Nordnet for at generere en CSV-fil, du kan bruge til Excel
Derfor tænkte jeg: Kan jeg automatisere dette udtræk, sådan jeg altid har opdateret data i mit Excelark? Ja, det kan jeg. Med Python. Her fortæller jeg om hvordan og deler min kode.
Hvordan snakker man http med Nordnet?
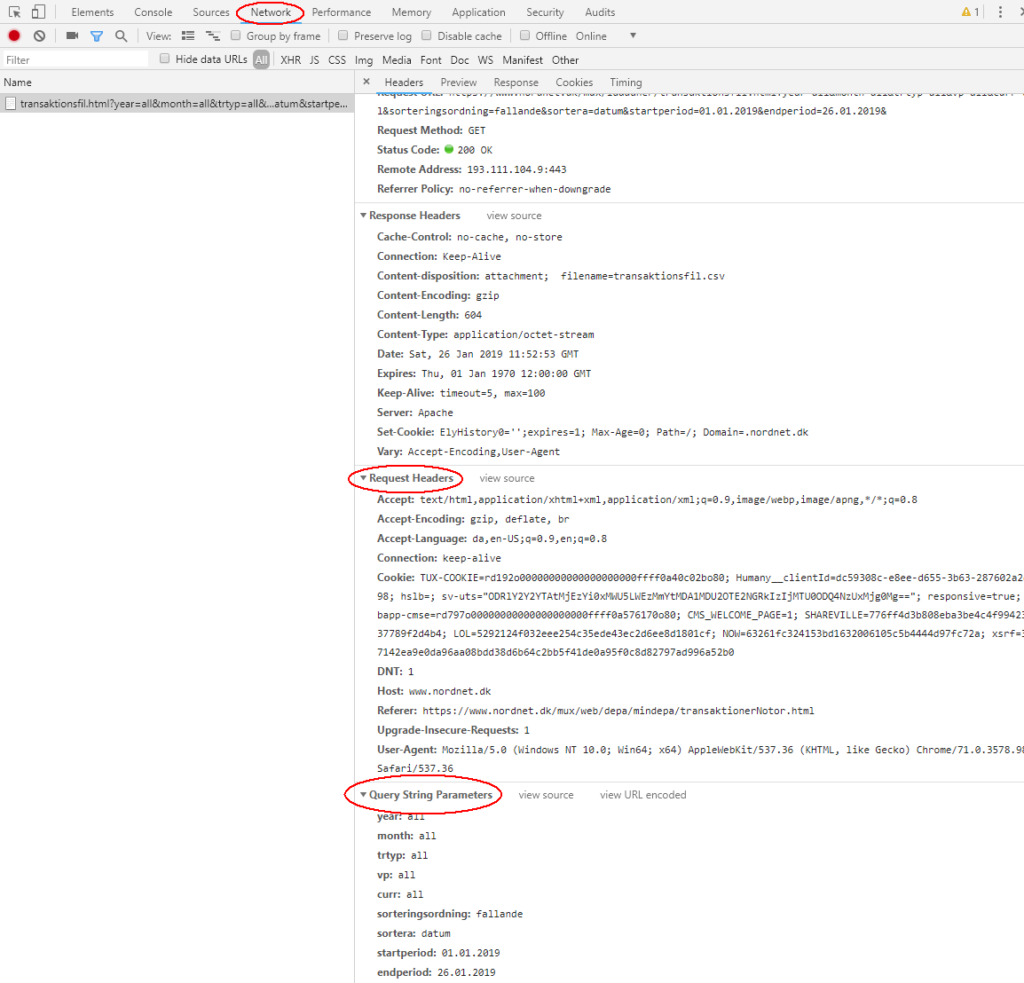
Det første jeg gjorde, var at undersøge hvad der egentlig sker, når jeg beder Nordnet om en transaktionsfil. Det gør jeg i Chrome ved at trykke F12, vælge Network og undersøge hvad min browser sender af sted for at få en CSV-fil tilbage. Jeg kan se, at der ryger en cookie af sted og nogle parametre, der handler om bl.a. sortering og periode for de transaktioner, jeg vil have ud:
I Python bruger jeg modulet Requests til at snakke med Nordnet og forsøger at konstruere noget der ligner det, min browser smider af sted. Efter at have prøvet mig frem, finder jeg ud af, at det er den cookie, der hedder NOW, der er afgørende for, at modtage noget fra Nordnet. Jeg laver en cookie-ordbog, der foreløbig indeholder min NOW-værdi fra Chrome:
cookies = {'NOW': '63261fc324153bd1632006105c5b4444d97fc72a'}
Min forespørgsel, der giver mig data tilbage, ser sådan ud:
# LOGIN TO NORDNET #
# First part of cookie setting prior to login
url = 'https://www.nordnet.dk/mux/login/start.html?cmpi=start-loggain&state=signin'
r = requests.get(url)
cookies['LOL'] = r.cookies['LOL']
cookies['TUX-COOKIE'] = r.cookies['TUX-COOKIE']
# Second part of cookie setting prior to login
url = 'https://www.nordnet.dk/api/2/login/anonymous'
r = requests.post(url, cookies=cookies)
cookies['NOW'] = r.cookies['NOW']
# Actual login that gets us cookies required for primary account extraction
url = "https://www.nordnet.dk/api/2/authentication/basic/login"
r = requests.post(url,cookies=cookies, data = {'username': user, 'password': password})
cookies['NOW'] = r.cookies['NOW']
cookies['xsrf'] = r.cookies['xsrf']
Når denne procedure er gennemført, kan jeg med den genererede NOW-værdi trække transaktioner ud af mit primære depot (det jeg oprettede først, da jeg fik en Nordnet-konto).
For at trække transaktioner ud fra andre depoter, undersøger jeg hvad der sker, når jeg vælger et andet depot i Nordnet. Det sker ved at forespørge https://www.nordnet.dk/mux/ajax/session/bytdepa.html med mine gemte cookies og værdien fra den cookie, der hedder xrsf i headeren. Tilbage får jeg en ny NOW-værdi, som jeg kan bruge til at hente transaktioner på det andet depot, og en ny xrsf-værdi, som jeg kan bruge, hvis jeg har endnu flere depoter, jeg får brug for at skifte til:
# Switch to secondary account and set new cookies
url = 'https://www.nordnet.dk/mux/ajax/session/bytdepa.html'
headers = {'X-XSRF-TOKEN': cookies['xsrf']}
r = requests.post(url,cookies=cookies, headers=headers, data = {'portfolio': item['id']})
cookies['NOW'] = r.cookies['NOW']
cookies['xsrf'] = r.cookies['xsrf']
Til sidst skal jeg finde en fornuftig struktur for mit program, finde ud af hvordan jeg får lavet en god struktur i min CSV-fil (nogle gange returnerer Nordnet en CSV-fil med en kolonne for meget). Og så har jeg brug for en mulighed for at tilføje manuelle linjer til min CSV-fil (fordi jeg gerne vil have historisk data med fra et gammelt depot hos en anden bank).
Det færdige program i Python
Her er det færdige program. Du er velkommen til at bruge det, videreudvikle, osv.
<pre class="wp-block-syntaxhighlighter-code"><p># -*- coding: utf-8 -*-
# Author: Morten Helmstedt. E-mail: helmstedt@gmail.com
""" This program logs into a Nordnet account and extracts transactions as a csv file.
Handy for exporting to Excel with as few manual steps as possible """
import requests
from datetime import datetime
from datetime import date
import os
# USER ACCOUNT, PORTFOLIO AND PERIOD DATA. SHOULD BE EDITED FOR YOUR NEEDS #
# Nordnet user account credentials and name of primary portfolio (first one listed in Nordnet)
user = ''
password = ''
primaryportfolioname = "Frie midler"
# Names and portfolio ids for all any all secondary portfolios. The id is listed in
# Nordnet when selecting a portfolio. If no secondary portfolios the variable
# secondaryportfolioexists should be set to False.
secondaryportfolioexists = True
secondaryportfolios = [
{'name': 'Ratepension', 'id': ''},
]
# Start date (start of period for transactions) and date today used for extraction of transactions
startdate = '01.01.2013'
today = date.today()
enddate = datetime.strftime(today, '%d.%m.%Y')
# Manual date lines. These can be used if you have portfolios elsewhere that you would
# like to add manually to the data set. If no manual data the variable manualdataexists
# should be set to False
manualdataexists = True
manualdata = """
Id;Bogføringsdag;Handelsdag;Valørdag;Transaktionstype;Værdipapirer;Instrumenttyp;ISIN;Antal;Kurs;Rente;Afgifter;Beløb;Valuta;Indkøbsværdi;Resultat;Totalt antal;Saldo;Vekslingskurs;Transaktionstekst;Makuleringsdato;Verifikations-/Notanummer;Depot
;30-09-2013;30-09-2013;30-09-2013;KØBT;Obligationer 3,5%;Obligationer;;72000;;;;-69.891,54;DKK;;;;;;;;;Frie midler
"""
# CREATE OUTPUT FOLDER AND VARIABLES FOR LATER USE. #
# Checking that we have an output folder to save our csv file
if not os.path.exists("./output"):
os.makedirs("./output")
# Creates a dictionary to use with cookies
cookies = {}
# A variable to store transactions before saving to csv
transactions = ""
# Payload for transaction requests
payload = {
'year': 'all',
'month': 'all',
'trtyp': 'all',
'vp': 'all',
'curr': 'all',
'sorteringsordning': 'fallande',
'sortera': 'datum',
'startperiod': startdate,
'endperiod': enddate
}
# LOGIN TO NORDNET #
# First part of cookie setting prior to login
url = 'https://classic.nordnet.dk/mux/login/start.html?cmpi=start-loggain&state=signin'
r = requests.get(url)
cookies['LOL'] = r.cookies['LOL']
cookies['TUX-COOKIE'] = r.cookies['TUX-COOKIE']
# Second part of cookie setting prior to login
url = 'https://classic.nordnet.dk/api/2/login/anonymous'
r = requests.post(url, cookies=cookies)
cookies['NOW'] = r.cookies['NOW']
# Actual login that gets us cookies required for primary account extraction
url = "https://classic.nordnet.dk/api/2/authentication/basic/login"
r = requests.post(url,cookies=cookies, data = {'username': user, 'password': password})
cookies['NOW'] = r.cookies['NOW']
cookies['xsrf'] = r.cookies['xsrf']
# GET PRIMARY ACCOUNT TRANSACTION DATA #
# Get CSV for primary account
url = "https://classic.nordnet.dk/mux/laddaner/transaktionsfil.html"
data = requests.get(url, params=payload, cookies=cookies)
result = data.text
result = result.splitlines()
firstline = 0
for line in result:
if line and firstline == 0:
transactions += line + ';' + "Depot" + "\n"
firstline = 1
elif line:
# Sometimes Nordnet inserts one semicolon too many in the file. This removes the additional semicolon
if line.count(';') == 22:
position = line.rfind(';')
line = line [:position] + line[position+1:]
transactions += line + ';' + primaryportfolioname + "\n"
# GET TRANSACTION DATA FOR ALL/ANY SECONDARY ACCOUNTS #
if secondaryportfolioexists == True:
for item in secondaryportfolios:
# Switch to secondary account and set new cookies
url = 'https://classic.nordnet.dk/mux/ajax/session/bytdepa.html'
headers = {'X-XSRF-TOKEN': cookies['xsrf']}
r = requests.post(url,cookies=cookies, headers=headers, data = {'portfolio': item['id']})
cookies['NOW'] = r.cookies['NOW']
cookies['xsrf'] = r.cookies['xsrf']
# Get CSV for secondary account
url = "https://classic.nordnet.dk/mux/laddaner/transaktionsfil.html"
data = requests.get(url, params=payload, cookies=cookies)
result = data.text
result = result.split("\n",1)[1]
result = result.splitlines()
for line in result:
if line:
# Sometimes Nordnet inserts one semicolon too many in the file. This removes the additional semicolon
if line.count(';') == 22:
position = line.rfind(';')
line = line [:position] + line[position+1:]
transactions += line + ';' + item['name'] + "\n"
if manualdataexists == True:
manualdata = manualdata.split("\n",2)[2]
transactions += manualdata
# WRITE CSV OUTPUT TO FILE #
with open("./output/trans.csv", "w", encoding='utf8') as fout:
fout.write(transactions)</p></pre>